Fix Sentry sourcemaps for AWS Lambda functions
- June 9, 2020
- serverless
- monitoring
Applications are pretty complex, so are the bugs we introduce while we are doing development on a random Tuesday afternoon.
Sentry provides error & crash monitoring that helps us discover and prioritize application errors in real-time. I assume you are familiar working with Typescript, Serverless Framework, and Sentry. I will use them going forward.
TLDR: you can find the source code of the solution here.
Let's start with the following serverless function handler:
| 1 | import { withSentry } from './with-sentry'; |
| 2 | |
| 3 | export const handler = withSentry(async () => { |
| 4 | throw new Error(`Some error.`); |
| 5 | |
| 6 | return { |
| 7 | statusCode: 200, |
| 8 | body: JSON.stringify({ |
| 9 | random: Math.random() |
| 10 | }) |
| 11 | }; |
| 12 | }); |
| 13 |
The withSentry higher-order function looks like this:
| 1 | import * as Sentry from '@sentry/node'; |
| 2 | |
| 3 | export const withSentry = <E>(handler: (event: E) => Promise<any>) => { |
| 4 | Sentry.init({ |
| 5 | dsn: process.env.SENTRY_DSN |
| 6 | }); |
| 7 | |
| 8 | return (event: E) => { |
| 9 | return handler(event).catch(async (error) => { |
| 10 | Sentry.captureException(error); |
| 11 | |
| 12 | await Sentry.flush(2000); |
| 13 | |
| 14 | return { |
| 15 | statusCode: 500, |
| 16 | body: JSON.stringify({ |
| 17 | message: `Something went wrong` |
| 18 | }) |
| 19 | }; |
| 20 | }); |
| 21 | }; |
| 22 | }; |
The error thrown in the handler function is caught by withSentry, and it's forwarded to Sentry. You get the notification about it and you are about to call it a day...
Then you check how the error looks like in Sentry:
| Error: Some error. |
| File "/var/task/src/get-random.js", line 1, col 1131, in u |
| '{snip} nction(){return o}));var n=t(0);const o=(u=async()=>{throw new Error("Some error.")},n.init({dsn:process.env.SENTRY_DSN}),e=>u(e).catch(asyn {snip} |
| File "/var/task/src/get-random.js", line 1, col 1197, in Runtime.o [as handler] |
| '{snip} or("Some error.")},n.init({dsn:process.env.SENTRY_DSN}),e=>u(e).catch(async e=>(n.captureException(e),await n.flush(2e3),{statusCode:500,bod {snip} |
| File "/var/runtime/Runtime.js", line 66, col 25, in Runtime.handleOnce |
| let result = this.handler( |
Holy Moly! 🤦♂️ It's hard to spot the line which threw the error. Our function was automatically transpiled and uglify-ed by Serverless, so it's all gibberish. But let's see why this happened and what we can do to improve it.
1. Configure webpack to generate sourcemaps
So first of all, we should generate sourcemaps. Sourcemaps are files that map our transpiled/transformed files back to the original source code. For example, if you have a typescript file called handler.ts and transpile it, 2 files will be generated: handler.js and handler.js.map.
Let's configure webpack to generate sourcemaps when we are creating a build:
| 1 | const slsw = require('serverless-webpack'); |
| 2 | |
| 3 | module.exports = { |
| 4 | devtool: slsw.lib.webpack.isLocal ? false : 'source-map', |
| 5 | // ... |
| 6 | }; |
| 7 |
2. Configure serverless to keep build directory and package functions individually
By default serverless will remove the build directory after packaging is done and our sourcemaps will be gone. Also we should make sure each function is packaged individually into their own folder.
| 1 | # ... |
| 2 | |
| 3 | package: |
| 4 | # ... |
| 5 | individually: true |
| 6 | |
| 7 | custom: |
| 8 | webpack: |
| 9 | # ... |
| 10 | keepOutputDirectory: true |
3. Rewrite frames sent by Sentry with the correct path
Your service usually contains more than 1 function. Somehow you should distinguish errors thrown in different functions. Creating 1 project for every function might be overkill, but you could create 1 project for every service you have, then you could group the errors by function in each service. To accomplish this we should rewrite the error stacktrace to modify the path of the file it was thrown in.
Do you remember what was the path of the script that threw the error in that gibberish message that we've seen in Sentry? No wonder you don't, so here it is: /var/task/src/get-random.js. Serverless packages your functions into different folders and then deploys them. AWS Lambda places your handler in /var/task. So your function from .webpack/getRandom/src/get-random.js will end up in /var/task/src/get-random.js when you invoke the deployed function.
We should rewrite stacktraces, so a file path /var/task/src/get-random.js would be converted into /var/task/getRandom/src/get-random.js
To do this, let's install the @sentry/integrations npm package:
| yarn add @sentry/integrations |
Let's use it in the Sentry configuration:
| 1 | import * as Sentry from '@sentry/node'; |
| 2 | import { RewriteFrames } from '@sentry/integrations'; |
| 3 | |
| 4 | const transformStacktrace = (frame: Sentry.StackFrame) => frame |
| 5 | |
| 6 | export const withSentry = <E>(handler: (event: E) => Promise<any>) => { |
| 7 | Sentry.init({ |
| 8 | dsn: process.env.SENTRY_DSN, |
| 9 | integrations: [ |
| 10 | new RewriteFrames({ |
| 11 | iteratee: transformStacktrace |
| 12 | }) |
| 13 | ] |
| 14 | }); |
| 15 | |
| 16 | return (event: E) => { |
| 17 | // ... |
| 18 | }; |
| 19 | }; |
You can read more about this Sentry integration. We should provide a function to this integration that takes a stacktrace frame and applies some transformations on it.
AWS passes the lambda function's name as an environment variable, AWS_LAMBDA_FUNCTION_NAME, in the format of {service}-{stage}-{function}, in this case random-service-local-getRandom. We can use this to retrieve the function's name (getRandom in this case).
(If you know a better way to get the function's original name, than parsing this environment variable, let me know.)
| 1 | import * as Sentry from '@sentry/node'; |
| 2 | import { RewriteFrames } from '@sentry/integrations'; |
| 3 | |
| 4 | const transformStacktrace = (frame: Sentry.StackFrame) => { |
| 5 | if (!frame.filename) return frame; |
| 6 | if (!frame.filename.startsWith('/')) return frame; |
| 7 | if (frame.filename.includes('/node_modules/')) return frame; |
| 8 | if (!process.env.AWS_LAMBDA_FUNCTION_NAME) return frame; |
| 9 | |
| 10 | const functionName = process.env.AWS_LAMBDA_FUNCTION_NAME.replace(/^.+-([^-]+)$/g, '$1'); |
| 11 | frame.filename = frame.filename.replace('/var/task', `/var/task/${functionName}`); |
| 12 | |
| 13 | return frame; |
| 14 | }; |
| 15 | |
| 16 | // ... |
After we added the above code snippet if an error is thrown in /var/task/src/get-random.ts it will be recorded as /var/task/getRandom/src/get-random.ts in Sentry.
Let's verify it by deploying our function (note: provide your own SENTRY_DSN):
| SENTRY_DSN="YOUR_SENTRY_DSN" yarn serverless deploy --stage local |
If everything went well, we should see something like this in the console:
| service: random-service |
| stage: local |
| region: eu-central-1 |
| stack: random-service-local |
| resources: 12 |
| api keys: |
| None |
| endpoints: |
| GET - https://xxxxxxxx.execute-api.eu-central-1.amazonaws.com/local/random |
| functions: |
| getRandom: random-service-local-getRandom |
| layers: |
| None |
To throw an error and to forward it to Sentry, we should invoke the function by accessing the endpoint:
| curl -v https://xxxxxxxx.execute-api.eu-central-1.amazonaws.com/local/random |
Now if you check your Sentry issue board, and select the most recent one, you should see something like this:
| Error: Some error. |
| File "/var/task/getRandom/src/get-random.js", line 1, col 1508, in a |
| '{snip} eplace("/var/task","/var/task/"+r),e},u=(a=async()=>{throw new Error("Some error.")},t.init({dsn:process.env.SENTRY_DSN,integrations:[new o. {snip} |
| File "/var/task/getRandom/src/get-random.js", line 1, col 1623, in Runtime.u [as handler] |
| '{snip} _DSN,integrations:[new o.RewriteFrames({iteratee:i})]}),e=>a(e).catch(async e=>(t.captureException(e),await t.flush(2e3),{statusCode:500,bod {snip} |
| File "/var/runtime/Runtime.js", line 66, col 25, in Runtime.handleOnce |
| let result = this.handler( |
It's still gibberish, but the path is correct: /var/task/getRandom/src/get-random.js.
4. Add release to the Sentry configuration
By setting a release in the Sentry configuration we can distinguish errors thrown by different deployments. Also soon we are going to upload the sourcemaps to specific releases, so stacktraces won't become broken after future code changes & deployments.
Let's configure Serverless to set the env variable to the function:
| 1 | provider: |
| 2 | # ... |
| 3 | environment: |
| 4 | SENTRY_DSN: ${env:SENTRY_DSN, ''} |
| 5 | SENTRY_RELEASE: ${env:SENTRY_RELEASE, ''} |
Then let's pass that environment variable to the Sentry configuration:
| 1 | export const withSentry = <E>(handler: (event: E) => Promise<any>) => { |
| 2 | Sentry.init({ |
| 3 | dsn: process.env.SENTRY_DSN, |
| 4 | release: process.env.SENTRY_RELEASE, |
| 5 | integrations: [ |
| 6 | new RewriteFrames({ |
| 7 | iteratee: transformStacktrace |
| 8 | }) |
| 9 | ] |
| 10 | }); |
| 11 | |
| 12 | // ... |
| 13 | }; |
5. Create a sentry release with the sentry-cli
Let's install the @sentry/cli npm package as a dev dependency to manage releases. You can read more about releases here.
| yarn add @sentry/cli --dev |
You can use your application's version as a Sentry release if you are using semver:
| export SENTRY_RELEASE=$(grep 'version' package.json | cut -d '"' -f4 | tr -d '[[:space:]]') |
Or you can use the commit sha:
| export SENTRY_RELEASE=$(git rev-parse HEAD) |
Or the cli can generate one for you:
| export SENTRY_RELEASE=$(yarn sentry-cli releases propose-version) |
You need to set a few env variables to tell sentry-cli how and where to upload the sourcemaps:
| export SENTRY_AUTH_TOKEN="your sentry auth token" |
| export SENTRY_ORG="your sentry org" |
| export SENTRY_PROJECT="your sentry project" |
Now you can use the sentry-cli without any problems. Let's create the release:
| yarn sentry-cli releases new ${SENTRY_RELEASE} |
6. Build & deploy your lambda function
Cool, so in order to generate the sourcemaps, we should build the service with webpack.
| SENTRY_DSN="YOUR_SENTRY_DSN" yarn serverless deploy --stage local |
You can see that a .webpack folder has been generated and it contains all your functions in different folders. Every folder contains your handler function and the sourcemap near it. Now you should upload these sourcemaps to Sentry.
| yarn sentry-cli releases files ${SENTRY_RELEASE} upload-sourcemaps .webpack --ignore node_modules --rewrite --url-prefix '/var/task' |
So we uploaded everything under the .webpack directory, except the node_modules folders and we prefix the files with /var/task. So our sourcemap from .webpack/getRandom/src/get-random.js.map will be uploaded as /var/task/getRandom/src/get-random.js.map.
Notice that this path is the same as the stacktrace paths of the error we threw in step 3.
You can navigate now to that release in Sentry to verify that all the files have been uploaded, and can be found under the release artifacts.
You can finalize the release by running:
| yarn sentry-cli releases finalize ${SENTRY_RELEASE} |
8. Profit
That's it. You got beautiful stacktraces.
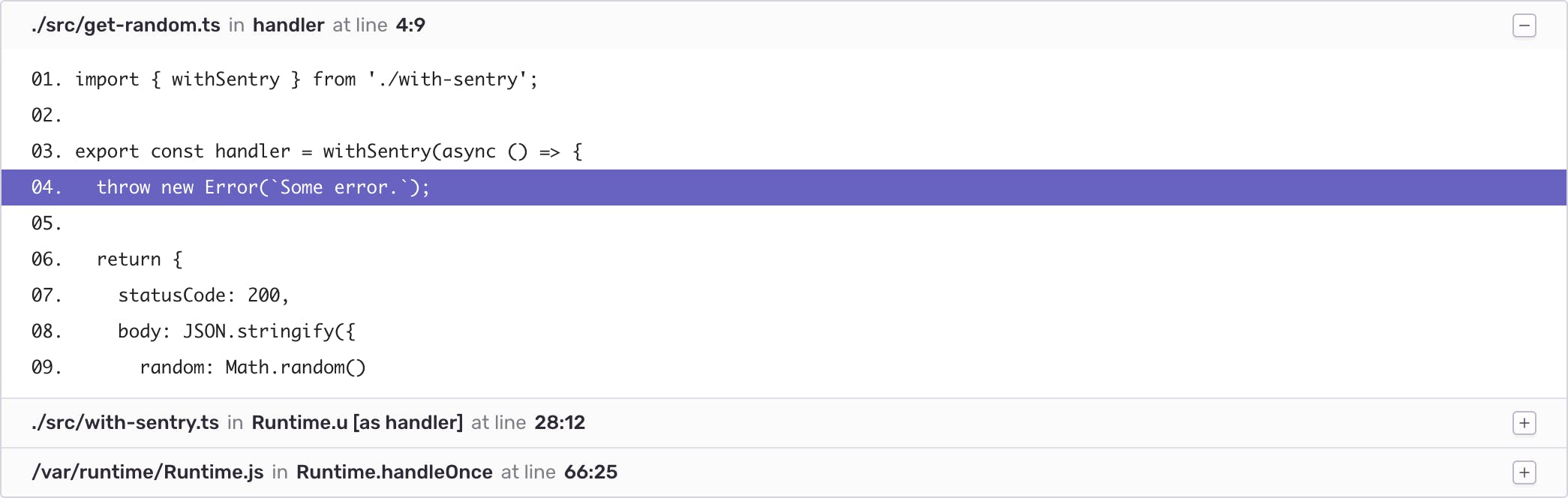
It might seem like a long process at first, but after you get familiar with Sentry, it should be a no-brainer.
For some extra points, I suggest adding more context to these errors, e.g. environment or trace id/correlation id.